
通俗易懂,小白也能看懂的文章。
prompt这个词相信学过一些大模型的同学都不陌生了,那这篇文章开头我们先来给不熟悉的同学讲几个概念。
prompt是什么?
大家平常在生活中很多时候都会用到Chatgpt、kimi、豆包这些大模型,但是大家知道他们是怎么工作的么?他们为什么可以回答你的问题?
prompt可以说是大模型的“引导者”,如果没有prompt,那大模型可能就和一个无头苍蝇一样,所以prompt是非常重要而且必要的。
所以,用更专业但是通俗点的话来说,提示词(prompt) 就是指用户输入给大语言模型(如ChatGPT)的文本内容,用于引导模型生成相应的回答或输出。提示词可以是问题、指令或上下文信息,帮助模型理解用户的意图和需求。
就是说,其实我们在和大模型对话的时候,我们问出的每个问题就是一个prompt,大模型就是基于我们给出的prompt进行回答的。
比如:
请你告诉我世界上最高的楼是什么?
我要实现…,请你给我输出实现他的python代码。
请你给我制定一个完善的英语学习计划。
上面这些常见的问题其实都是提示词。
prompt可以分为两部分 系统提示词(system prompt) 和 **用户提示词(user prompt)**,那我们输入的问题就是用户提示词,系统提示词一般大模型在面向用户发布之前Prompt工程师就写好了。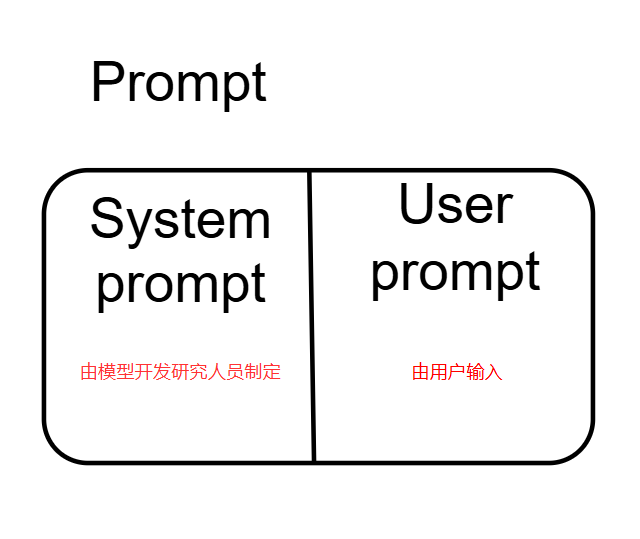
为什么要学习prompt工程?
好的,在上面一部分,我们已经大致了解了prompt到底是什么了。
那现在这个部分其实就是讲prompt工程有什么用?他是用来干什么的?
什么是提示词工程?
提示词(prompt)是你给大模型的具体输入,而提示词工程(Prompt engineering)就是设计和优化提示词(prompt)以获取大模型的最佳回答的过程。
那为什么我们要学习提示词工程呢?
可以理解为提示词就是我们的工具,假设现在我们需要去挖胡萝卜,那如果我们输入的prompt是经过提示词训练之后输出的,可能就对应的是铁铲子,如果只是平平无奇的一个问题,那可能我们的工具只有我们的手。那用手能不能挖到胡萝卜呢?能,但是挖的大小和效率和铲子就完全不能比了。
学习提示词工程,就是学习提问的技巧,更好的提问方式得到的回答也会更让人满意。
怎么写好的prompt?
这个问题可以用上个问题来回答,写好的prompt就是要学习PE(提示词工程)。
这里就来实际的告诉大家有哪些方法和注意事项。
学习prompt的本质就是了解大模型和了解自己,在你清楚这两点之后,那利用AI(chatgpt、kimi、豆包等 )工具你将可以实现大部分你想实现的东西。
了解大模型
所谓了解大模型,就是要弄清楚下面几个问题。
我们可以用大模型做什么?
大模型是怎么干活的?
大模型怎么能更好的干活?
首先,
我们我们可以用大模型干什么?
我觉得大模型什么都可以干,帮你写代码,当你的心情导师,帮你练习英语……可以说,只要问得好,那他就是万能的!
大模型是怎么干活的?
大模型的工作是基于统计和概率,而不是基于对文本的正确性的。
大模型的学习数据规模量是非常大的,如果他每次的计算和回答都带入全量的数据,那这个资源耗费量可太大了。这个概率怎么理解呢?比如你输入一个”喝”,那他可能就判断你下一个词是”水、踩、饮料”等等。
但是这样也有问题,因为我们用来训练的数据,都是基于特定的场景下的,比如我训练大模型,那我问RAG是什么?他可能会给我回答是大模型中的RAG策略,但是我如果是医学领域的学生呢,那我可能想获取的信息是RAG是重排酶。
所以这时候也不能完全靠概率,这时候就要提到两个技术概念,一个是词向量生成技术,一个是Transformer中的attention自注意力机制。
什么是词向量生成技术呢?首先,大模型会对用户输入的文本进行Token分词,将原始文本分解成更小的token单元。
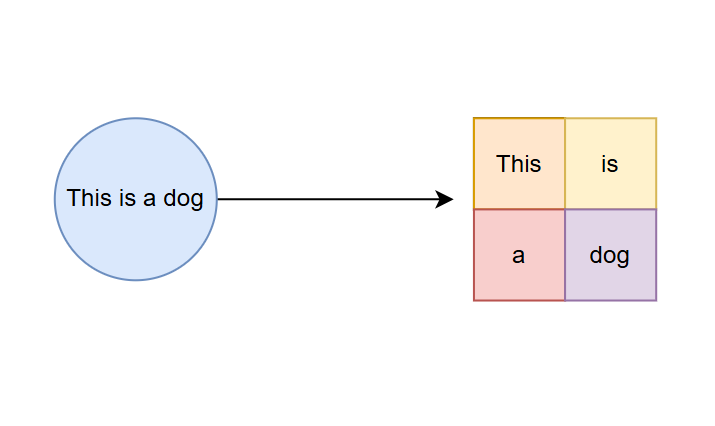
但是这时候我们也只是把句子拆分成了一些单词,要让大模型可以直接计算,我们还需要把这些单词转化为数值向量,这就是向量化。具体来说,模型会将每个token映射到一个高维的向量空间,我们通过Emdeding model嵌入模型来实现。
比如下图,我们就将上面那段话,转化成了对应的向量。
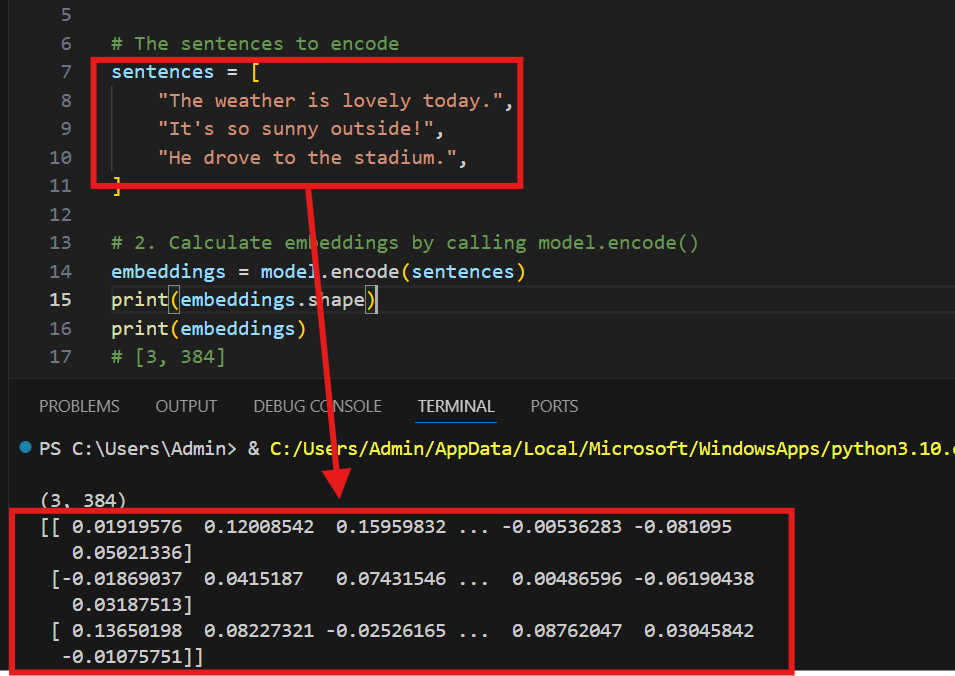
这样一来就节约了很多资源,提高了效率,并且根据向量之间的相近关系,能大大提高我们的概率。
再通俗的理解一下,想象一下,我们有一大堆词语,比如“猫”“狗”“苹果”“电脑”。计算机无法像人一样直接理解词语的意思,所以我们需要一种方法让计算机“理解”这些词。
词向量机制就是给每个词分配一组数字(就像给每个词一个坐标),让计算机可以“理解”词语之间的关系。比如,“猫”和“狗”可能会有相近的坐标,因为它们都是动物,而“苹果”和“电脑”的坐标差距可能会大一些。通过这种机制,计算机可以识别哪些词语更相似。
那自注意力机制是干嘛的呢?
自注意力机制是让计算机更好地关注句子里重要的词。想象你在读一句话,可能某些词比其他词更重要。比如在句子“我喜欢吃苹果,因为苹果甜”里,“喜欢”和“甜”可能是关键。自注意力机制帮助计算机在句子里找到这些关键词,并给它们分配更多的“注意力”,这样计算机可以更好地理解句子的意思。
通过自注意力机制的学习结果是“模型把海量的数据通过相似度进行关联的存储,形成自己的关系网”,这样可以让模型更加准确的输出我们想要的东西。
大模型怎么才能更好的干活?
对于这个问题,我们可以代入一下,代入大模型。假设现在你的leader叫你写个python脚本,那你想想需要什么呢?
首先得有诉求,这个脚本需要干什么呢,这个脚本的功能是啥这你得知道;然后你得有编译这个脚本的工具;最后你得编写代码啊,你得有你自己的思路或者方法去编写。
那对于大模型也是一样的,我们让他干活首先得告诉他,我们需要他做什么。
那现在比较下面两种说法,觉得哪种提问会让他回答得更好呢?
请你帮我做一个记录我每天进度的工具,这个工具需要能够帮助我追踪我每天学习的内容。我希望它能够支持以下功能:首先,能够添加新的学习任务,每个任务需要有一个截止日期,并且需要支持对任务的优先级进行设置(比如高、中、低)。其次,在学习过程中,我可以记录任务的进展情况,像是“正在进行中”、“已完成”或“待开始”。另外,如果有任务不再需要做了,应该可以方便地删除该任务。而且,如果可能的话,这个工具还应该能够提供每天、每周或每月的任务总结报告。最终,任务完成后,还应该能够根据完成的时间和任务优先级对任务进行排序,最重要的任务排在最前面。你觉得用哪种编程语言适合实现这个功能呢?我听说Python可以处理这些任务,所以我想知道你的建议。如果你觉得Python合适的话,那就按照这个语言来做吧。总的来说,我希望这个工具操作起来简单直观,并且功能全面。
用python语言创建一个任务追踪工具,能够添加、更新、删除任务,设置优先级和截止日期,记录任务进展,并提供任务总结报告和排序功能。
答案无疑是第二个,第一种输入显得繁杂无序,很难让人理解真的想要的东西是什么,大模型同理。
所以第一点,我们输入的 user prompt 应该尽可能清晰简短,用尽量短的话清晰完整的讲清楚我们的诉求。
那到了工具部分,我们这里的工具就是指大模型的选择啦,这里尽量选择一些应用比较广泛比较成熟的大模型,或者代码能力比较好的,比如Chatgpt、豆包、Kimi等等。
最后就是我们写代码的思维了,这个思维和我们的知识存储有关系,和我们的思维方式有关系。那大模型呢,它的回答是基于现有的知识通过深度学习模型预测的,那有没有一种可能,它没有学习过这个知识,它也预测不了,那这时候会怎么办呢?一种可能是它直接告诉你它没有这方面的知识存储,另一种可能就是它不懂装懂,它给你胡说八道一大堆,这也就是我们所说的大模型幻觉现象。
怎么有效降低这种现象出现的可能性呢?
这里就要提到很有用的RAG策略啦,这个策略我们后面会单独写一篇文章来讲,这里我们只需要知道有了这个策略相关给大模型搞了个外挂,类似于开卷考试,我们把相关的资料给到大模型,大模型发现已有的知识他解决不了你的问题的话,它就会学习你给它的那些资料。
这里就清楚了大模型的回答是怎么来的了,那思维呢?大模型回答我们问题的思维方式是什么样的?这里又涉及到另外一个知识点,就是COT,也叫做思维链。这里也不需要深入过多了解。我们只用知道,有了COT,我们就可以让大模型输出它的思考过程,或者按照我们给它的思考步骤进行思考解决,并且输出它的思考步骤,这样一来大模型也有了自己的思考过程并且可以输出给我们,大大提高了他的逻辑性和准确率。
最后其实大模型也像个小孩子一样,需要多多鼓励,适当的给他一些情感刺激他会回答的更好,比如:你的回答对我来说很重要,你一定可以帮我很好的回答这个问题的、如果答对了奖励你一顿火锅……
了解自己
现在你已经对大模型有了一个初步的了解,而了解自己呢,也是需要问自己几个问题:
我想要让它做什么?
我该怎么清楚的告诉我它的诉求?
我该怎么更好的让它理解?
我想要让它做什么?
在让大模型帮你解决问题之前,你要想清楚自己的诉求到底是什么。如果你自己都没弄清楚自己要什么的话,大模型听不懂也不奇怪了。
我该怎么清楚的告诉它我的诉求?
那我知道我现在的想让它帮我解决的问题之后,该怎么清楚的让大模型知道你的真正需求呢?
很重要的一点就是告诉它你所处的背景。很多时候所处的背景不一样,大模型给出你的回答也不一样,如果你啥也不说,它只会猜概率,猜测哪个可能是你需要的,那就给你哪个。这时候你就会说,Chatgpt啥也不是。我为什么会强调这一点呢,因为我确实在这一点上踩过很多坑。
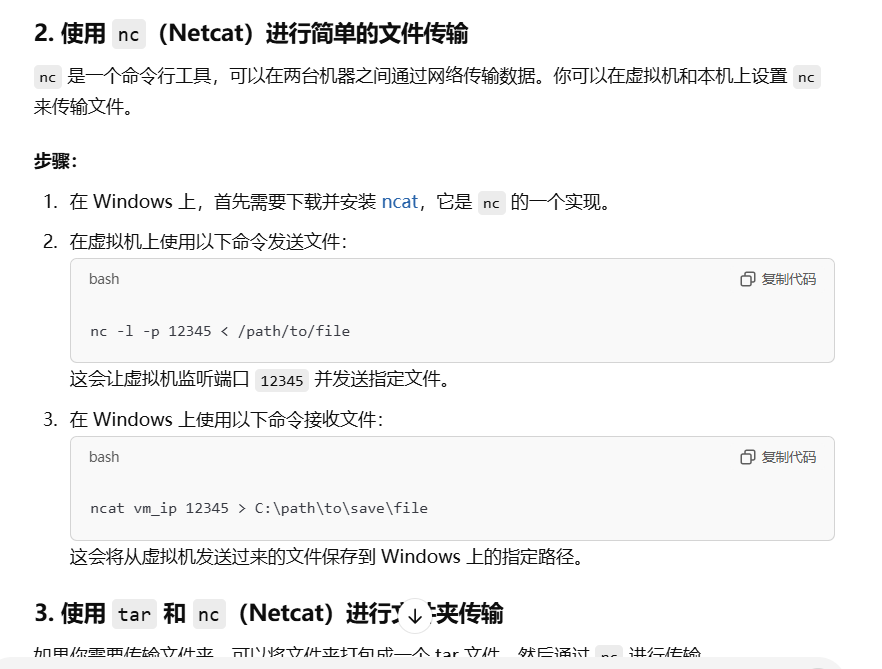
比如,现在你在做一个渗透测试,你拿下了机器的命令行,发现桌面有个可疑软件,你需要把他传到你本机中打开查看,但是你发现你只能操控命令行,并且scp命令不能用,那怎么办呢?
如果你只问某个关键结果,那你得到的回答可能是这样的:

因为这些回答的方法用的人最多。这时候很明显没有给出你满意的回答,于是你换了一种问法。他就会给出你很多理想的解决方法。

我该怎么更好的让它理解?
那模型怎么才能更好的理解我的诉求呢?
进行角色扮演
可以把大模型想象成百变超人,想让他变成什么人什么职业的时候,就和他说,让他变!
比如想让它帮你代码,你就以“**你是一个互联网公司的高级程序员,现在你需要…**”开头如果可以的话,指定完成任务所需的步骤
如果你让他完成的任务比较复杂或者你的要求比较高,可以将任务分解为若干个简单的步骤。
但是要注意,每个步骤应该专注一单一的操作或者指令,最好可以按照“**首先…,第二步…,然后…**”这种清晰明了的步骤来。
然后步骤数量不要太多,最好5个以内,大模型的注意力也是有上限的,如果太多步骤他可能回答的就不是很好了。提供参考资料
当你觉得他回答的某些问题不太好的时候,可以给他一些参考文本,比如你让他回答关于某个领域新的研究成果,你可以把相关论文一起作为输入给他。
以上就是我个人对prompt的一些理解并且尽量用通俗易懂的话语告诉大家,欢迎批评指正~