
常见评估大模型的指标以及其运用场景举例(通俗易懂版!)
我们生活中或者是工作中很多地方会用到大模型,那我们怎么去评估一个大模型他的效果是否好,是否符合我们的要求和标准呢?或者说我们该从哪些指标中知道我们还有哪些地方需要改进呢?
今天就给大家介绍几个在大模型的训练中常见的几个评估指标。
这里先写几个比较常见,而且对于新手小白比较好理解的~
常见的评估指标
在了解下面这些常见评估指标之前,我们先了解几个机器学习中的概念。
TP,TN,FP,FN的理解
TP(True Positive):预测正例,实际结果也正(系统说对了)
TN(True Negative):预测负例,实际结果也负(系统说对了)
FP(False Positive):预测正例,实际结果却是负(系统说错了)
FN(False Negative):预测负例,实际结果却是正(系统说错了)
我们做个表格理解一下:
| 指标 | 解释 | 类比 |
|---|---|---|
| TP | 预测作弊且确实作弊 | 抓到了真正的作弊者 |
| TN | 预测没作弊且确实没作弊 | 没冤枉无辜的学生 |
| FP | 预测作弊但其实没作弊 | 冤枉了好人 |
| FN | 预测没作弊但其实作弊 | 漏掉了真正的作弊者 |
好啦,接下来我们就来看看常见的一些评估指标吧。
1️⃣ 准确率 (Accuracy)
定义:预测正确的比例。类比:
想象你是老师,班上有100个学生,期末考试你要判断每个学生是“及格”还是“不及格”。
- 如果你正确判断了90个学生的成绩(不管及格还是不及格),那么准确率就是:
准确率 = 90 / 100 *100%= 90%总结:
准确率只看总的预测正确率,但不关心错误的细节。
计算即:预测正确的/总预测数
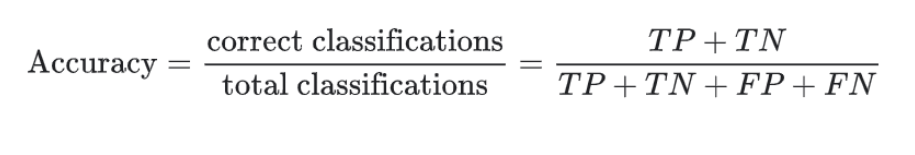
2️⃣ 精确率 (Precision)
定义:预测为正的样本中,有多少是真正的正样本。类比:
假设你要找出班上作弊的学生(正样本),但你错把一些没作弊的同学也当成了作弊的。
- 你标记了10个学生为作弊,但实际上只有8个是真的作弊,2个是冤枉的。
精确率 = 8 / (8 + 2) = 80%总结:
精确率关注的是你说对了多少——在预测为“正”的样本中,真正正确的有多少。
计算即:预测为正例并且确实为正例的例子/预测为正例的例子
3️⃣ 召回率 (Recall)
定义:所有正样本中,你找出了多少。类比:
假设班上总共有10个学生作弊,但你只找出了8个,还有2个漏掉了。
- 召回率 = 8 / 10 = 80%
总结:
召回率关注的是你找全了吗——你预测出来的正样本,覆盖了所有正样本的多少。
计算即:预测为正例并且确实为正例的例子/实际所有正例
召回率也叫真正例率,所以同时还有对应着的误报率(假正例率)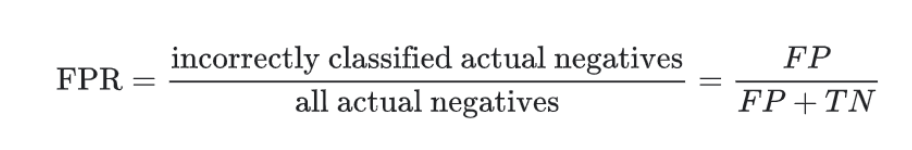
计算即:预测为正例但是实际为反例的例子/实际所有反例
4️⃣ F1分数 (F1-Score)
定义:精确率和召回率的平衡点。类比:
如果你只追求精确率(避免冤枉人),你可能会漏掉很多真正的作弊学生。
如果你只追求召回率(尽量多抓人),你可能会抓错很多无辜的学生。
F1分数就是在精确率和召回率之间找平衡,用公式:
总结:
F1分数是平衡精确率和召回率的综合指标,适用于精确率和召回率都很重要的场景。
5️⃣ ROC曲线 (ROC Curve)
定义:描述模型的真阳性率(召回率) 和 假阳性率(误报率) 之间的关系。类比:
假设你有一个金属探测器,你可以调整灵敏度。灵敏度越高,更多的金属会被探测到(召回率高),但也会误报一些非金属物品(误报率高)。
- ROC曲线就是当你调整探测器灵敏度时,召回率和误报率之间的变化情况。
总结:
ROC曲线能帮你看到模型在不同阈值下的表现,并选择合适的阈值。
6️⃣ AUC值 (Area Under the Curve)
定义:ROC曲线下面积的大小。类比:
AUC值就是金属探测器的“好坏评分”。分数范围是0.5到1:
- AUC = 0.5:完全随机猜测(比如瞎蒙)。
- AUC = 1:完美模型。
总结:
AUC值越大,模型就越好,说明它在不同阈值下都能稳定地把正负样本区分开。
什么时候重点关注什么指标?(应用场景)
上面介绍了几个指标,但是大家会有这样一个疑问么:如果这些指标在某些情况下的数值差别很大的时候,我应该更重点关注哪个指标?
其实该重点关注什么,取决于这个指标重点影响什么,而所影响的东西在对应场景下对我们的重要性就决定了我们最应该关注的东西。
- 准确率 (Accuracy) 适用的场景
- 定义:所有预测中,预测正确的比例。
- 适用场景:正负样本数量大致平衡,且误报和漏报的成本相近。
举例: - 学生考试成绩判定:
系统只需正确判断及格或不及格,没必要特别关注误判或漏判的代价。 - 天气预报(简单情况):
系统预测晴天和下雨的准确率更重要,只要总体准确就够了。
总结:
当正负样本平衡且误报漏报代价相近时,准确率是很好的指标。
- 精确率 (Precision) 重要的场景
- 定义:在所有预测为正的样本中,真正为正的比例。
- 适用场景:你更关心避免误报(FP),不想冤枉无辜的人或对象。
举例: - 垃圾邮件检测系统:
如果误判了重要的邮件(FP),把它丢进垃圾箱,会造成用户损失。
重点:提高精确率,减少误报。 - 疾病诊断筛查(非终极诊断):
如果诊断系统说一个健康人患有重病(FP),可能会引起恐慌和不必要的治疗。
总结:
当误报的代价很高时,要重点关注精确率。
- 召回率 (Recall) 重要的场景
- 定义:在所有正样本中,被成功预测为正的比例。
- 适用场景:你更关心不漏掉正样本(FN),即使多报一些无所谓。
举例: - 癌症筛查:
如果漏掉了一个真正的癌症患者(FN),可能会导致悲剧。因此,宁愿误报一些无病患者(FP),也不能漏掉。 - 安全系统的异常检测:
在金融欺诈或黑客入侵检测中,漏掉一次攻击可能会带来巨大损失。因此尽可能地抓住所有异常。
总结:
当漏报的代价很高时,要重点关注召回率。
- F1分数 (F1-Score) 重要的场景
- 定义:精确率和召回率的调和平均。适用于需要平衡两者的场景。
举例: - 搜索引擎:
搜索结果要确保用户能找到所需内容(召回率高),同时不希望显示太多无关内容(精确率高)。
重点:用F1分数来平衡精确率和召回率。 - 医疗AI辅助诊断:
精确率和召回率都很重要:既不能漏诊,也不能误诊太多。
总结:
当精确率和召回率都很重要时,使用F1分数来平衡它们。
- AUC-ROC 曲线
- 定义:AUC衡量模型在不同阈值下的整体表现。
- 适用场景:当需要衡量模型在不同阈值下的稳定性时。
举例: - 银行信用卡欺诈检测:
银行可以根据不同需求调整模型的阈值(严格或宽松),而AUC可以全面反映模型的性能。
如果AUC接近1,说明模型在各种阈值下表现都很好。
总结:
当模型的阈值需要动态调整时,使用AUC-ROC来综合评价模型。
我们来总结一下:
| 指标 | 重点场景 | 何时使用 |
|---|---|---|
| 精确率 | 垃圾邮件过滤、疾病诊断等 | 当误报代价高时,减少冤枉无辜者。 |
| 召回率 | 癌症筛查、欺诈检测等 | 当漏报代价高时,尽可能抓住所有正样本。 |
| F1分数 | 搜索引擎、AI辅助诊断等 | 当精确率和召回率都很重要时,求平衡。 |
| 准确率 | 考试成绩判定、天气预报等 | 当正负样本平衡且误漏报代价相近时。 |
| AUC-ROC | 银行欺诈检测等 | 当模型需要在不同阈值下表现良好时。 |
上面就是一些大模型常见评估指标的定义和运用场景啦,如有错误或者有疑问,欢迎给我留言或者私聊我~